文章段落
BigQuery Data types,Functions
part 2
String字串功能
文字的運用應該是在資料庫裡最普遍使用,BQ內建了很多文字運用的語法功能。請看一下範例
with string as (
select * from unnest ([
‘Taipei’, ‘New York’, ‘Singapore’
]) as city
)
select
city
, LENGTH(city) as len
, LOWER(city) as lower
, STRPOS(city, ‘or’) as orpos
from string
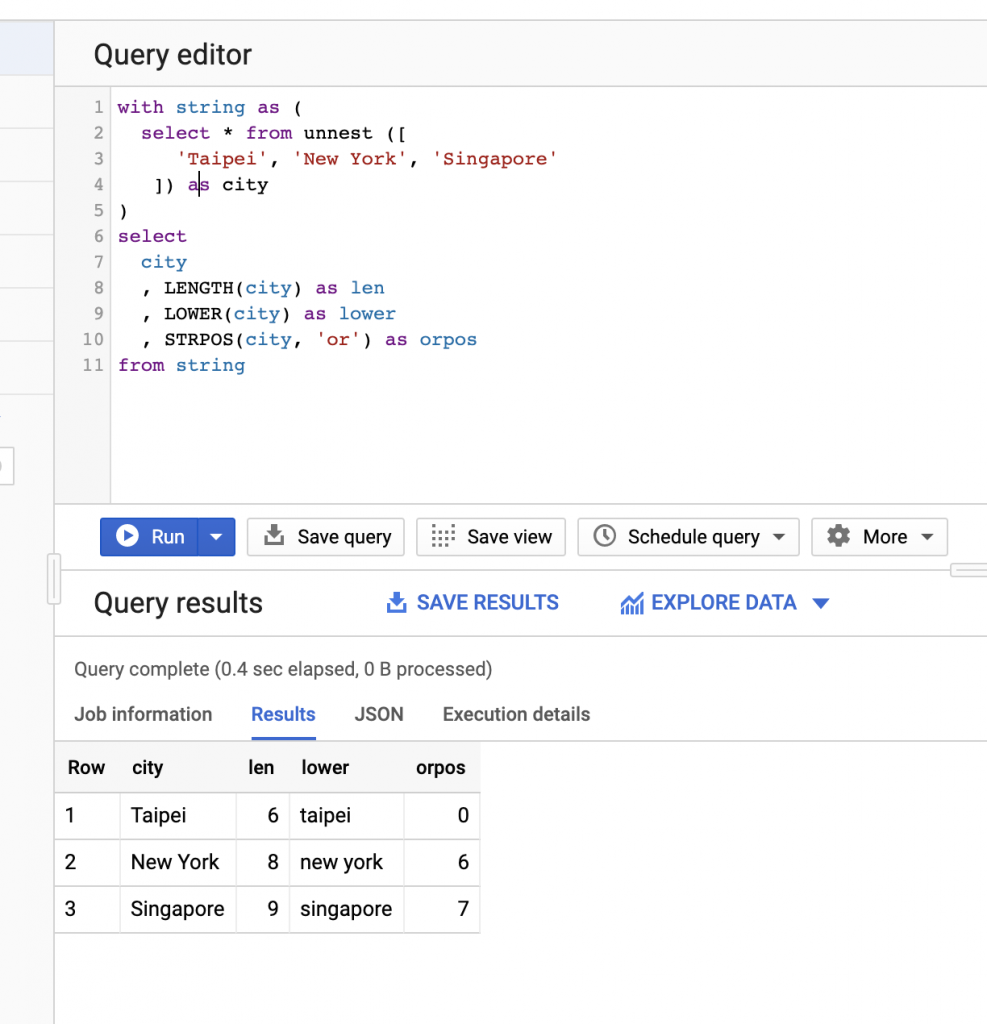
上面的範例是將資料計算字元數還有將字串變成小寫,還有尋找在city欄位中”or”這個字是在字串的第幾位,因為Taipei沒有帶”or”的字,故顯示是0.
讓我們再看下一個範例
with emailaddress as (
select ‘jason@gcp.com’ as email, ‘Annapolis, MD’ as city
union all select ‘Ellen@gcp.com’, ‘Boulder, CO’
union all select ‘Aaron@gcp.com’, ‘Chicago, IL’
)
select
CONCAT(
SUBSTR(email, 1, STRPOS(email, ‘@’) – 1), — username
‘ from ‘, city) as claaers
from emailaddress

上面範例我們使用的CONCAT的條件式將文字組合起來,先用STRPOS去算email @符號在哪一位置之後用SUBSTR擷取email欄位裡 @ 後的字串。
在這裡我們用到了文字字串常用的分離SUBSTR與組合CONCAT。
再來我們看一下字串裡語係的問題,由於BQ是使用Unicode所以它是建立在英語的基礎上的。我們看以下範例
with string as (
select * from unnest([
‘Taipei’, ‘New York’, ‘มุมไบ’, ‘東京’
]) as city
)
select
city
, UPPER(city) as allcaps
, CAST(city as BYTES) as bytes
from string
上面的例子我們可以看到,BQ對於每種語係的bytes在Unicode之下的狀況,接下來我們看一下在詳細的字串分析內容
with string as (
select * from unnest([
‘Taipei’, ‘New York’, ‘มุมไบ’, ‘東京’
]) as city
)
select
city
, char_length(city) as char_len
, To_Code_Points(city)[ORDINAL(1)] as first_code_point
, Array_Length(To_code_points(city)) as num_code_points
, CAST(city as Bytes) as bytes
, Byte_Length(city) as byte_len
from string

上面的字串的內容分析可以看到每個語言有更多不一樣的地方,所以在處理文字時若遇到語係問題需要特別注意。
另外在BQ中我們還可以針對文字字串在直接做 ETL的處理,我們以下針對以下範例來看BQ在文字的判斷與處理的語法
Select
Ends_with(‘Hello’, ‘o’) –true
, Ends_with(‘Hello’, ‘H’) –false
, Starts_with(‘Hello’, ‘h’) –false
, Strpos(‘Hello’, ‘e’) –2
, Strpos(‘Hello’, ‘f’) — o for not-found
, Substr(‘Hello’, 2, 4) — 1-based
, Concat(‘Hello’, ‘World’)

底下的範例是針對文字做變化處理
Select
LPAD(‘Hello’, 3, ‘&’) — 從左邊開始加&
, RPAD(‘Hello’, 3, ‘$’) — 從右邊開始加$
, LPAD(‘Hello’, 5)—從左邊開始加空白
, LTRIM(‘ Hello ‘) —去除左手邊的空白
, RTRIM(‘ Hello ‘) —去除右手邊的空白
, TRIM(‘ Hello ‘) —兩邊的空白都去掉
, Trim(‘%%%%Hello%%%’, ‘%’) –去掉兩邊的%符號
, Reverse(‘Hello’) —保留這個字串

再來我們看一下正規表示式
我們以郵遞區號來當作範例,台灣的郵遞區號是3+2,五碼的數字。
SELECT
columns
, REGEXP_CONTAINS(columns, r’\d{5}(?:[-\s]\d{4})?’) has_zipcode
, REGEXP_CONTAINS(columns, r’^\d{5}(?:[-\s]\d{4})?$’) is_zipcode
, REGEXP_EXTRACT(columns, r’\d{5}(?:[-\s]\d{4})?’) the_zipcode
, REGEXP_EXTRACT_ALL(columns, r’\d{5}(?:[-\s]\d{4})?’) all_zipcodes
, REGEXP_REPLACE(columns, r’\d{5}(?:[-\s]\d{4})?’, ‘???’) masked
FROM (
SELECT * from unnest([
‘12345’, ‘1234’, ‘12345-9876’,
‘jas 12345 on’, ‘Cloud-ace’,
‘12345 Jas 34567’, ‘12345 9876’
]) AS columns
)

從上面的範例正規表示式有幾個部分說明一下
1. \d{5} –表示任何連續的5個數字
2. 另一個是每一個正規表示中跟在 括弧中前後的問號(?)的部分,這是為了分離連字號及空白鍵(/s)的部分
3. 另外表示式中的 \d \s 可能會發生一些問題所以最前面我們用r來修正這個問題
4. 第二行表示式我們用了 ^(開頭)及 $(結尾)兩個符號來尋找正確的有5位數的區碼
5.第三行我們使用 REGEXP_EXTRACT將符合條件的擷取出來,若有對應不到的就返回NUll值
6. 第四行 REGEXP_EXTRACT_ALL不一樣的是若對應不到的返回空值
7. 最後一個是 REGEXP_REPLACE,就是把符合條件的用另一個符號替換掉,這一個功能在有一些狀況需要隱藏機密資料時特別有用,例如信用卡號碼。
接下來我們看timestamp,請參考以下範例
select t1, t2, Timestamp_diff(t1, t2, Microsecond)
from ( select
Timestamp “2020-04-06 12:26:00.50” as t1,
Timestamp “2020-04-06 13:26:00.50+1” as t2,
)

從上面的例子我們可以看到兩個時間t1及t2的兩個時間表示方法沒有時間上的差異,BQ所使用的timestamp時間格式是遵照ISO8601(https://www.iso.org/iso-8601-date-and-time-format.html)。比較標準的timestamp當然是按照上面的表準作法來表示,但有時來自使用者的需求卻常常不是這樣。讓我們看下一個範例
select
format, input, zone
, parse_timestamp(format, input, zone) as ts
from (
select ‘%Y%M%d-%H%M%S’ format, ‘20200207-134500’ as input, ‘+8’ as zone
union all select ‘%c’, ‘Thu Jan 2 21:21:00 2020’, ‘Asia/Taipei’
union all select ‘%x %X’, ’04/06/18 15:10:00′, ‘GMT’
)

從上面的例子可以看到當我們輸入的資料如同第二列與第三列的格式時,使用parse_timestamp的功能我們可以把這些時間資料轉換成標準格式。同理我們也可以把標準格式轉換成我們想要的格式,請參考如下範例
select
ts, format
, Format_timestamp(format, ts, ‘+8’) as ts_output
from (
select current_timestamp() as ts, ‘%Y%M%d-%H%M%S’ as format
union all select current_timestamp() as ts, ‘%c’ as format
union all select current_timestamp() as ts, ‘%x %X’ as format
)

上面的例子可以看到我們將標準格式轉換成我們所需要的時間格式,我們可以注意到若沒有指定時區哪麼時區都會將是UTC,所以這一點需要特別注意。這是使用雲端服務與地端機房時會有這個差異。這在判讀一些有時間序列特性的資料例如系統的log或交易紀錄若沒有注意到,判讀上會產生很大的誤差。
我們也可以判讀一個日期,它是在一年的第幾週與這週的哪一天。請參考如下範例
select
ts
, Format_timestamp(‘%c’, ts) as represent
, Extract(DayOfWeek from ts) as dayofweek
, Extract(Year from ts) as year
, Extract(Week from ts) as weekno
from (
select Parse_timestamp(‘%Y%m%d-%H%M%S’, ‘19470227-193000’) as ts
)

當然我們也可以針對在BQ裡紀錄的時間來做修改/修正,請參考如下範例
SELECT
EXTRACT(TIME FROM TIMESTAMP_ADD(t1, INTERVAL 1 HOUR)) AS plus_1h
, EXTRACT(TIME FROM TIMESTAMP_SUB(t1, INTERVAL 10 MINUTE)) AS minus_10min
, TIMESTAMP_DIFF(CURRENT_TIMESTAMP(),
TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 MINUTE),
SECOND) AS plus_1min
, TIMESTAMP_DIFF(CURRENT_TIMESTAMP(),
TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL 1 MINUTE),
SECOND) AS minus_1min
FROM (SELECT
TIMESTAMP “2016-06-24 15:30:00.45” AS t1
)

在上面例子中,我們使用了 timestamp_add/timestamp_sub/timestamp_diff等功能將時間抽取出來比對加入我們需要的時間差。
BQ的時間長度可以容許很大的,例如年份可從0-9999年。這是因為BQ使用了 8 bytes來計算timestamp,像MySQL只有4 bytes相對範圍就很小。
最後我們來看一下BQ處理GIS經維度的問題,我們用一個public dataset來做範例,這資料來自美國人口普查局有關全美道路的經緯度,我們preview資料內容

我們可以看到每個州(每一列)裡都有很多經緯度的資料,我們怎麼找某一經緯度在哪一州呢?請參考下面範例
SELECT
state_name
FROM `bigquery-public-data`.utility_us.us_states_area
WHERE
ST_Contains(
state_geom,
ST_GeogPoint(-75.19, 40.58))

我們使用ST_GeogPoint功能來解析地理位置,BQ是採用SQL/MM 3的規格。功能類似Postgres中 PostGIS library。以上就是簡單的介紹BQ的資料型態與功能。
下一篇,我們將教大家如何把資料載入BQ中。

