
文章段落
大數據應用已被落實在零售與媒體等眾多產業,而其目標可分為三大類,不同目標所需的分析工具和方法都不盡相同。跟著 Cloud Ace 一起認識大數據應用的常見目標、步驟、分析工具與針對不同目標的實踐建議,更輕鬆地實踐大數據應用吧!
大數據應用案例
● 零售業:日本 7-Eleven
● 媒體業:美麗佳人(Marie Claire)
● 資訊軟體服務業:多利曼(QSearch)
大數據應用―迷思
大數據分析為近年來最熱門的領域之一,隨著運算科技發展、資料量急速成長,和儲存設備成本降低等趨勢,大數據分析已脫離單純的資料處理,進化為協助企業擴展思維及商業模式,並進一步預測未來的工具。
因此,很多一頭熱地跟上這股熱潮的人並不清楚自身的分析需求,縱使已有分析目標,也多面臨不知道或不熟悉該使用哪些工具等問題,導致分析最後無疾而終。而除了分析目標外,充足的資料量也是不可或缺的要素。所以,要達成完善且精確的大數據分析,明確的目標和足量的資料是缺一不可的。

因此本文將主要根據上述應用迷思,提供各位分析資料前需思考的問題,了解當前是否已具備明確的分析目標。另外也會分享 Google Cloud Platform(GCP)上有關大數據分析的服務,並針對三大常見應用目標提供解決方案建議。
大數據應用―目標與案例
大數據分析和一般的資料分析一樣需要一個明確的目標來推動,而若缺乏目標,最後分析的結果不僅可能無法為企業帶來價值,過程中投注的金錢、人力和時間也會付諸流水。因此 Cloud Ace 在此為大家整理出三個資料分析中主要的應用目標類型,讓各位可在著手分析資料前,先確認自身目前的需求,在資料分析的路上少走一些冤枉路。
現狀分析
首先,在思考分析目標時如毫無頭緒,可先從現狀分析著手,透過數據了解當前狀況。現狀分析簡單來說就是單純透過公司歷史資料,了解到過去幾年發生過的事情,並進一步洞察公司現階段整體的營運狀況。

比如我們想知道過去一年公司每個月的利潤,就可藉由繪製利潤走勢圖,查看這一年內公司整體營運狀況是正成長還是負成長。又比如想了解 Q1~Q2 產品的銷售狀況,可繪製圓餅圖來查看各項產品的銷售佔比,掌握在 Q1 及 Q2 這兩季度內,銷售量最高和最低的產品分別為何。另外現狀分析也是許多大數據解決方案的基礎(如:全方位顧客輪廓分析),如果有綜合多種分析目標的需求,歡迎進一步參考 Cloud Ace 提供的客製化專案開發服務,打造更彈性多樣化的分析專案。
原因分析
因為現狀分析只能觀察到整體性的結果,所以想深入了解導致這些結果的原因,就必須進一步做原因分析。因此所謂的原因分析,就是透過分析可能導致現狀分析結果的因素,去推斷當下整體結果背後的具體原因,協助企業以「治本」的方式解決問題或下決策。

沿用前一段的例子,假設我們透過現狀分析發現公司整體利潤在近一年內下降5%,而利潤因為與公司的營收及營業成本息息相關,所以在執行原因分析時就可藉由分析營收與成本的相關數據,探究導致整體利潤下降的原因為何。在這個例子中,營收相關數據包含商品價格、銷售量和銷售折扣等;而成本相關數據則有店租、材料價格與員工薪水等。這些項目在資料集中都應有相對應的欄位,所以分析時可分別從這些欄位下手。

最後,分析結果除了可單純透過折線圖、柱狀圖或圓餅圖呈現,也可兩兩比較,觀察不同數據彼此間是否存在相依性。假設我們發現產品銷量和人力成本皆與利潤成正比,就可思考在人力成本不變的情況下,利潤降低原因可能是銷量降低。反之如果銷量不變,則可進一步研究人力成本的哪個因素是影響利潤的主因。
預測分析
原因分析可協助企業制定決策,而預測分析則是評估決策的重要工具。不論是要確保新決策實質上能為公司帶來正面影響,亦或只是單純依據現階段的策略來預測未來(幾秒、幾天或幾年後)的趨勢或行為,預測分析都有其必要性,因為它可用來簡化作業流程、提高收益及降低風險。

舉例來說,倘若我們透過原因分析發現利潤降低的主因是庫存成本提高,那利用預測分析模型預測產品庫存,就更能確保公司針對降低產量(例:從每月生產1,000個滑鼠降至每月生產850個滑鼠)所下的決策是合理且適當的。
又比如公司推出新產品時想預測哪類舊客群購買意願較高,也可透過預測分析篩選出可能會對新產品感興趣的顧客,寄送 EDM 並附上舊客專屬回饋來更精準地誘導回購。因此無論是運用統計演算法、預測模型或是機器學習等方式,預測分析都可協助企業更精準地洞見未來、規劃決策,以及挖掘過去不曾注意到的潛在商機。
大數據應用―步驟與分析工具
具備分析目標與足量資料後,就可著手準備分析資料了,以下將分別介紹大數據分析的四大步驟:資料前處理、資料儲存、資料分析和資料視覺化。另外也會同時帶大家了解 GCP 上有哪些產品可滿足以上四個步驟,以及不同產品的搭配條件有哪些。
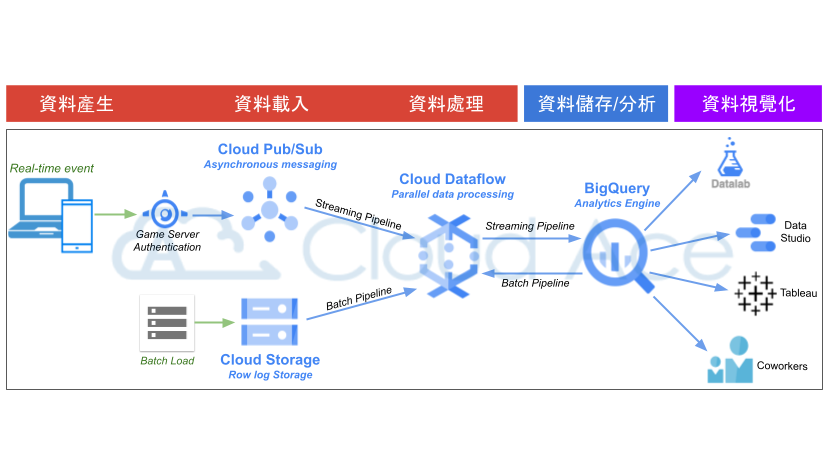
資料前處理(ETL)
首先,我們最初拿到的資料集通常都是原始資料(Raw Data),而這些 Raw Data 是不能被拿去做任何分析的!因為未經處理的 Raw Data 常會有資料格式不正確、不一致、空值很多,或編碼錯誤等問題,也就是所謂的髒數據。因此,在執行大數據分析時,資料前處理往往會花費許多時間,透過了解整份資料每個欄位所代表的意義,進而根據這些欄位決定該如何處理與清洗,讓整份資料集變成一份可分析的資料,步驟雖然繁瑣但也至關重要。

資料前處理其實就是大家耳熟能詳的 ETL(Extract, Transform, Load),在 GCP 上,除了可單純使用 BigQuery,還可再搭配 Cloud Dataflow 與 Cloud Pub/Sub。針對即時資料(Streaming Data),資料產生時會觸發 Cloud Pub/Sub 並立即透過 Cloud Dataflow 加以處理。而針對批次資料,則可透過外部工具或自行撰寫的排程程式,將資料傳送到 Cloud Storage(GCS)後,再由 Cloud Dataflow 進行資料處理(詳見下圖)。
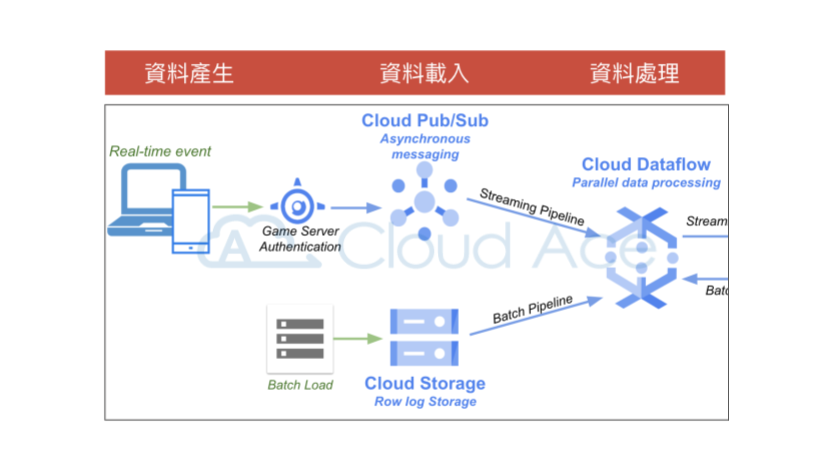
其中 Cloud Dataflow 屬於全代管的資料處理服務,不僅可自動安排資料處理流程、部署及管理資源處理作業,還可藉由水平調度工作站資源,提高資源使用率以符合成本效益。另外諸如 Dataprep、Dataproc 和 Data Fusion,也都是 GCP 上實用的資料處理工具,下面簡單介紹這三項工具的用途。
首先,Dataprep 可透過圖形介面(無需編寫程式碼)瀏覽、清理及準備相關資料(結構化與非結構化資料),也能處理任何規模的資料,自動偵測結構定義、資料類型及異常(如缺值、離群值和重複值),此外還會建議及預測最合適的資料轉換作業。而 Dataproc 則像是 GCP 上的「全代管式」 Apache Hadoop、Spark 叢集。最後,Data Fusion 和 Dataprep 一樣提供圖形介面,使用者無須編寫程式碼就可部署 ETL/ELT 資料管道(Data Pipeline)。
資料儲存
透過 GCP 完成自動化處理與清洗資料後,就可以將這些乾淨的資料匯入資料倉儲(Data Warehouse)中,也就是 ETL 中的 L(Load)。有人也許會問,為什麼不直接把 Raw Data 放入資料倉儲清洗後再做分析呢?原因其實很簡單,因為資料倉儲主要是存放乾淨、Schema 一致(準備被分析)的資料;資料湖(Data Lake)才主要用來存放來自不同來源的 Raw Data,保留資料原始格式。所以資料倉儲基本上只負責分析而不負責清洗。

在 GCP 上,GCS 及 BigQuery 是兩大最常用的資料儲存服務。通常,GCS 會被作為 Data Lake 使用;BigQuery 則被作為資料倉儲使用。其中 BigQuery 屬於無伺服器服務(Serverless Service),不僅容易管理,還具備 SQL 查詢介面,此外也支援即時(Streaming pipeline)或批次(Batch pipeline)的資料匯入。想查看更詳細的介紹可以參考《BigQuery 是什麼?大資料時代一定要認識的最強資料分析工具》一文。
資料分析
有乾淨的資料儲存在資料倉儲後就真的可以開始分析了!如果不是太複雜的分析,可直接利用 BigQuery 的 SQL 查詢介面分析資料,或使用標準 SQL 語法建立或執行機器學習(Mechine Learning,ML)模型。另外,前面提到的資料處理工具 Dataflow 和 Dataproc ,也都能作為資料分析的輔助。Dataflow 有即時 AI 功能,可建構各種智慧解決方案,包含預測分析、異常偵測、即時個人化和其他進階分析用途等。而 Dataproc 則可透過 Apache Spark ML 執行機器學習,或搭配 BigQuery 進行分析。

最後,GCP 也有推出預測分析所需的相關服務,除了上述所提的 BigQuery ML,Vertex AI 與 AutoML 的搭配也很推薦!因為我們不用會寫 Code,就可快速建立與訓練模型。如要以自訂工具建立 ML 模型,也能用少少的 Code 訓練出好模型,使用門檻低之外成效也很顯著。
資料視覺化
最後,在資料視覺化上最常使用的就是 Looker Studio(原 Google Data Studio)。易於理解的互動式 Dashboard 圖像報表讓我們可以在一份報告中即時比較、過濾和組織所需要的確切資料。另外,Looker Studio 可連接的資料來源端也很豐富,除了 Google 本身的 BigQuery、Cloud SQL 和 Google Sheet,也支援 AWS 的 Redshift。若想了解如何將資料串接 Looker Studio,可參考《BigQuery 串接 Google sheet 及 Looker Studio 視覺化功能教學》。
截圖自:Looker Studio 官網|©2022 Google
大數據應用―建議
以上分別介紹了大數據分析的目標類型,和 GCP 上的資料處理工具,但兩者該如何搭配呢?三大分析目標分别適合使用哪些工具?以 ETL 這個環節為例,即使建立了自動化 Data pipeline,但根據分析情境不同,ETL 的架構也會大相逕庭。因此,以下提供大數據分析三大目標建議採用的解決方案,幫助大家在確立目標後,能快速掌握架構雛形和後續可能會用到的工具。
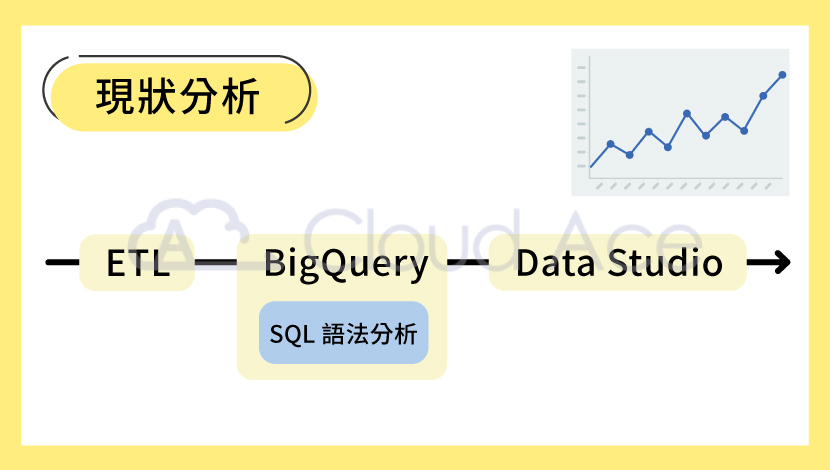
現狀分析的建議
以現狀分析這個目標來說,因為需分析的主要都是公司歷史資料(比如:近一年的每月利潤),基本上不會處理到 Streaming Data,也不會涉及到太複雜的分析語法,所以在資料做完 ETL 匯入 BigQuery 後,再透過 BigQuery 中 SQL 查詢介面裡的 SQL 語法分析就可以了。最後,只要再將結果匯入 Looker Studio,就能產出折線圖或圓餅圖等視覺化報表。
原因分析的建議
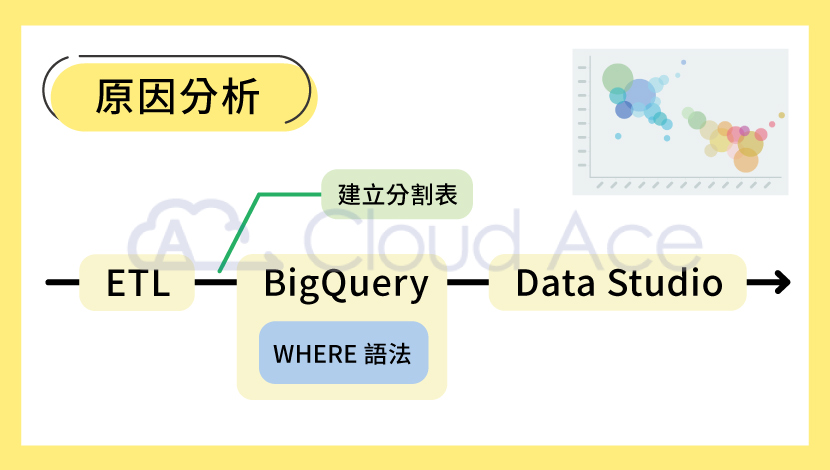
而原因分析其實與現狀分析狀況類似,所以也可以單純使用 BigQuery 分析,再用 Looker Studio 做視覺化圖表。但因為造成現狀分析結果的因素可能有百百種,像是營收來源和營業成本就各自涵蓋了許多因素,因此在做原因分析時,可能會用到大量的 SQL 查詢。而使用 BigQuery 查詢很容易忽略的盲點就是收費方式,BigQuery 的其中一項收費標準是「查詢量」,所以在資料匯入時建議先建好分割表(Partitioned Tables),再透過篩選條件(例如:WHERE 語法)減少查詢範圍,將查詢量控制到最小,避免帳單出現預期外的高額費用。
預測分析的建議
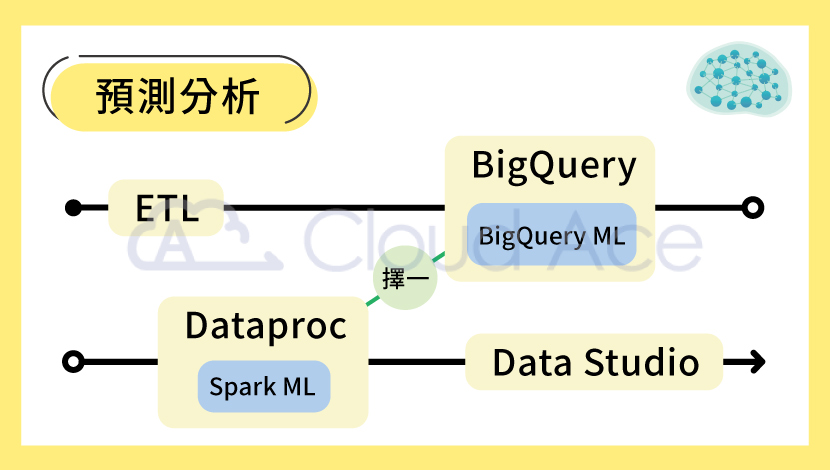
最後,預測分析因為會預測公司未來的利潤趨勢、成長幅度、成本花費和銷量等內容,所以可能會用到機器學習或演算法等工具。如果預算有限,建議可直接在 BigQuery 使用 BigQuery ML ,或如果本身熟悉且有在使用 Spark,也可以利用 Dataproc 進行 Spark ML 機器學習,提高數據預測精準度。
以上介紹了大數據分析常見的目標、基本的分析流程和相對應的 GCP 產品,最後也分享了不同分析目標的解決方案建議。想更了解如何完整匯入、分析和呈現資料,可參考《如何透過 Firebase 與 BigQuery 來進行分析》這篇文章。有客製化的大數據分析需求,可參考我們的數據分析方案,或直接聯繫我們獲得更多資訊!
▋延伸閱讀:
・BigQuery 是什麼?大數據時代一定要認識的最強資料分析工具
・BigQuery 教學―操作界面與分析、視覺化步驟完整圖解
・BigQuery SQL 語法基本操作 part 1
・BigQuery –匯入資料 part 1
・如何掌握GCP各台主機的成本?利用BigQuery的Label語法教學



