文章段落
雲端資料庫 Cloud SQL,是 Google 提供的 PostgreSQL、MySQL 與 SQL Server 等資料庫的代管服務。一起在 Cloud Ace 架構師的介紹下,了解 Google 的全代管雲端資料庫 Cloud SQL 的架構、4大重要功能與最佳實踐方式!
雲端資料庫是什麼?優點為何?
雲端資料庫是在雲端上建置、部署和存取的資料庫,和傳統地端資料庫一樣,可分為關聯資料庫和非關聯資料庫。而 Cloud SQL 是 Google 推出的關聯雲端資料庫,可代管 PostgreSQL、MySQL 與 SQL Server 等常見資料庫。它除了讓使用者可在快速啟用資料庫的同時享有讀寫分離同步、自動備份與監控整合等代管服務,Cloud SQL 身為雲端原生服務而具備的網路整合性,也讓我們能更安全便捷地將它連接 Google 的各項產品,並延伸使用儲存的資料。
雲端資料庫 Cloud SQL 代管 HA 架構
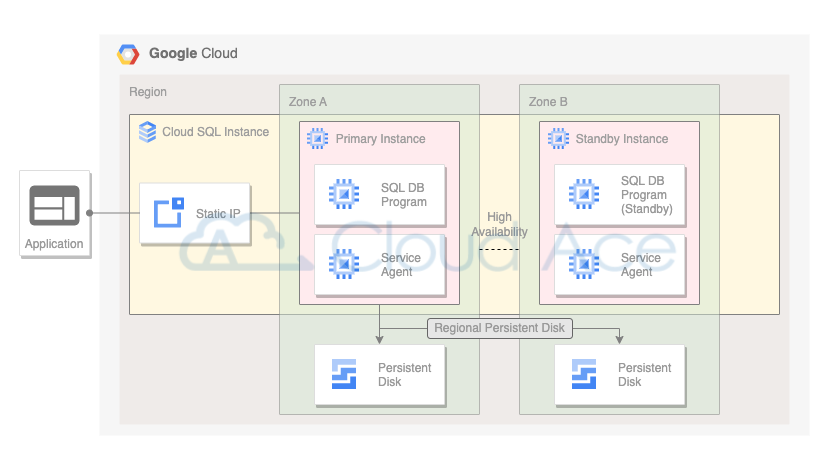
如同大部分的代管服務,每一個 Cloud SQL Instance 皆會部署資料庫伺服器在 Google 代管的網路環境裡,並搭配 Service Agent 做 Logging 與 Monitoring 的整合。下圖是一個開啟了 High Availability(HA)的 Cloud SQL Instance 架構。可以看到 Cloud SQL 作為 Regional 服務,其 Instance 的建立是按照 Zone 去部署,而 HA 的實踐便是在不同的 Zone 進行 Standby Instance 的部署,並搭配 Regional Persistent Disk 達到資料的跨 Zone 同步寫入。因此當今天 Primary Instance 出現服務異常,Regional Persistent Disk 便會掛載至 Standby Instance 來提供服務。
雲端資料庫 Cloud SQL 4大主要功能
上面我們提到了 Cloud SQL 作為 Google 的全代管資料庫服務,其提供的主要服務與代管的架構說明。下面我們進一步介紹這些服務的作用與背後的執行流程,以方便大家更好理解 Cloud SQL 具體可以做到的事情並能加以應用。

High Availability(HA)
我們可以把開啟 HA 服務的 Cloud SQL Instance 稱為一個 Regional Instance,這代表當今天一個 Zone 的機房發生異常,或是主機本身出現異常(如記憶體不足)時,我們的服務可以無痛地從其他 Zone 提供資料的讀存作業。
如同上面介紹的 Cloud SQL 架構,當我們對 Instance 開啟 HA 服務,Google 便會在不同 Zone 為我們創建一台 Standby Instance,並透過 Regional Persistent Disk 確保資料的跨 Zone 同步能力,以利異常狀況發生時執行 Failover 作業。雖然 HA 提供了強大的備援能力,但相對的我們也需要為此支付額外的設置費用,所以讀者在選擇是否開啟 HA 時,需審慎評估自身需求。
Read Replica
Cloud SQL 作為強大的雲端代管資料庫,自然要有能應對大量使用需求的擴展資源功能,就是所謂的 Read Replica。Read Replica 顧名思義就是指針對讀取資料庫的請求設置僅供讀取的 Instance,減少對 Primary Instance 的負荷,增加服務效能並提高服務供給的擴展性。
除了可以用在讀寫分離的架構, Read Replica 還有其他多元的使用方法。如利用 Read Replica 的 Promote 功能與可設置在不同 Region 的特性,達到跨 Region 的資料庫搬遷。或是利用其可指定地端或其他公有雲平台的資料庫當作 Primary Instance,來達到跨環境的搬遷作業。

Read Replica 還有一個很有趣的功能叫做 Cascading Replica,也就是給予 Read Replica 設置 Read Replica。透過這樣的方式,一來可減少 Primary Instance 對多台 Read Replica 的資料抄寫負荷,二來當今天我們需要將 Read Replica Promote 成新的 Primary Instance 時,可延續其掛載的 Read Replica 結構與提供的 Entrypoint。
Backups
Backup 顧名思義就是備份。在 Cloud SQL 上,提供了 On-demand 與 Automated 兩種備份機制。前者提供隨時的手動備份,使我們可以在非定義的備份時段進行臨時備份,且該備份不會被自動刪除,可長時間保存。通常建議在要做一些對資料庫有影響的操作前執行這項功能來保護我們的資料。
而 Automated Backup 則是透過設定執行備份的 Backup Window,指定要於每天的哪4小時內執行自動備份。該備份預設保存7天,也就是保留在最新的7個 Backups,但保留時間可透過修改設定來指定。一般會建議 Backup Window 的設定時段應選在資料庫操作頻率最低的時間段執行,避免影響效能或產生預期外的錯誤。
Point-in-time recovery
所謂的 Point-in-time recovery(PITR),就是透過 Binary Logs(Binlog)這個紀錄資料庫 Transaction 操作細節的二進制日誌,來倒回資料庫狀態至特定時間點。一般是在系統發生錯誤導致資料遺失時,用來恢復資料庫至錯誤發生前的狀態,減少因錯誤產生的資料缺失成本。
Cloud SQL Instance 創建時,預設就會開啟這項服務,但要特別注意的是,使用 PITR 時我們不能直接在既有的 Instance 進行恢復,因為 Cloud SQL 會創建一台繼承了原本 Instance 設定的新 Instance 來提供恢復時間點的資料。且開啟 PITR 意味著我們必須收集額外的 Binlog,即產生額外的儲存成本,所以操作時請特別注意 Binlog 的儲存時效設定。
雲端資料庫 Cloud SQL 4大最佳實踐方式
在 Cloud SQL 服務的使用上,雖然我們會期待代管資料庫能幫我們處理所有的資料庫管理作業並自動優化使用效率,但畢竟資料庫服務在不同的軟體架構上都有獨特的客製化需求,所以 Google 僅能在建置與維運上給予輔助。因此在資料庫應用上 Google 透過多種最佳實踐方式協助我們做規劃,下面我們就從架構面了解有哪些常見的優化方法吧。
以微服務架構分散資料庫單元
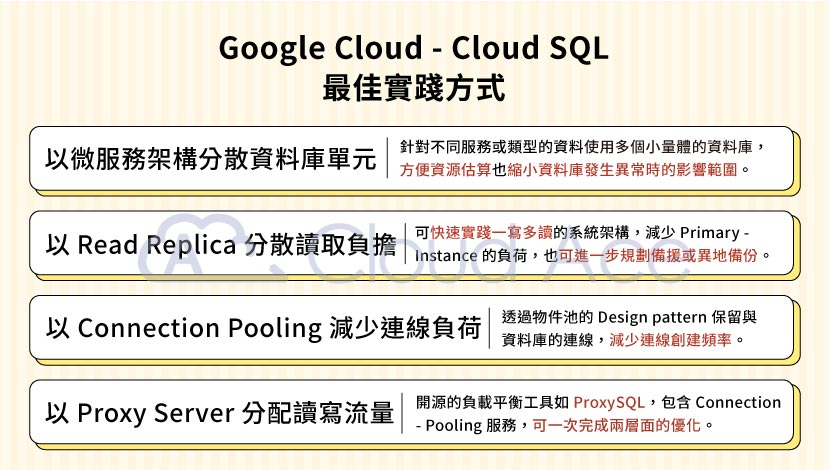
如同現代化的軟體服務架構精神,在 Cloud SQL 資料庫規劃上,Google 也建議使用微服務的架構。針對不同服務或類型的資料使用多個小量體的資料庫,一來在資源估算上可更直觀地判斷,二來也能縮小資料庫異常造成的服務受影響範圍,畢竟我們都知道雞蛋不該放在同一個籃子裡。
以 Read Replica 分散讀取負擔
同上所述,微服務架構的思維除了可應用在各項服務使用獨立的資料庫,也可對資料庫的讀寫做分離規劃。透過 Cloud SQL Read Replica 的簡易建置流程,我們能快速實踐一寫多讀的系統架構,減少 Primary Instance 的負荷。我們甚至能進一步規劃備援或異地備份方案,在 Primary Instance 異常事件發生時,快速將 Read Replica 轉為新的 Primary Instance。

以 Connection Pooling 機制減少連線負荷
所謂的 Connection Pooling 即是透過物件池的 Design pattern 保留與資料庫的連線,以減少創建連線的頻率並有效降低運算資源的消費。許多 Java 或 C# 的應用框架會內建搭載這樣的機制,但在一些比較輕量的程式語言如 Python 或 Go,便需自行建置。Google 建議我們最好透過這樣的機制控管與 Cloud SQL 的連線,避免達到其預設的連線量上限。
以 Proxy Server 分配讀寫流量
前面有提到我們可透過 Read Replica 來分流讀寫流量,但 Cloud SQL 預設沒有提供對應的負載平衡服務,僅提供 Read Replica 的連線窗口讓我們自己串接使用。所以如果我們有多個 Read Replica 需自動分流,或是希望更細緻地控管讀寫流量,Google 建議我們使用一些開源的負載平衡工具,如 HAProxy 或 ProxySQL 來建立分流系統,而這些工具一般就包含了 Connection Pooling 的服務,可一次完成兩個層面的優化作業。
以上就是全代管資料庫 Cloud SQL 的介紹,包含它的代管架構、四大功能和最佳實踐方式,後續我們也會再分享透過 Cloud SQL for MySQL,以 ProxySQL 建置讀寫分離的負載平衡架構實作。針對文中內容如有任何問題都可留言詢問,有進一步的技術疑問或想更認識 Google Cloud,也歡迎聯絡 Cloud Ace 獲得更進一步的資訊。
▋延伸閱讀:
・GCP 是什麼?可以拿來吃嗎?完整介紹 Google Cloud Platform
・【K8s 是什麼】比較 Docker 容器、K8s 和 GKE 的架構與優勢
・BigQuery 是什麼?大數據時代一定要認識的最強資料分析工具
・Cloud Run 是什麼?6大特色介紹與實作教學
・什麼是負載平衡?原理、6大 GCP Load Balancer 完整介紹