
文章段落
DevOps 由 Development 和 Operations 結合而成,代表一種文化、實踐和工具的結合。其核心概念是解決開發與維運,甚至是測試部門間的衝突,以提高組織交付應用程式和服務的能力。但究竟開發與維運部門為甚麼需要 DevOps?Google SRE 工程師是如何實踐 DevOps 的呢?一起來了解吧!
DevOps 是什麼?
根據維基百科「上一版」的定義是這樣子寫的: DevOps 是過程、方法和系統的統稱,促進 Development、Opeartion和QA部門間的溝通、協作與整合。
有沒有很籠統的感覺?XD
看一下圖好了
這圖到底是什麼意思呢?難道我們沒有 DevOps 就沒有溝通、沒有協作、沒有整合嗎?
這個我也會畫啊!我再畫一圈然後寫 HR,然後說導入 DevOps 可以更有效使用人力,再畫一圈 Finance ,然後說導入 DevOps 可以節省人力成本,乾脆再畫一圈,然後直接寫 Money 好了,代表導入 DevOps 可以發大財,你開心,我開心,大家都開心!感覺好像都沒錯耶!?
其實它這樣畫是有原因的,而且非常具體的原因。我們先來看一下這張圖:
為什麼要 DevOps?導入 3 大優勢
避免穀倉效應
隨著公司持續成長,系統的規模、功能、複雜度、事件和更新次數變多,有很多額外的工作,必須要手動處理回應各項事件。
而公司通常在應用程式的發展,通常分開發和維運,有些會再有測試部門,而開發和維運部門由於不同的背景、技能、目標和激勵措施不同,容易產生衝突。
- 開發:「我做了一個超炫的功能,什麼時候可以上線?」
- 維運:「不要停機、不要更新、不要掛掉。」
如果今天突然程式發生重大錯誤事件,就會變這樣:
- 開發:「都是你沒上新版,我在新版已經解決這個Bug」
- 維運:「你還敢說,上個月那一版,一部署網站就全部掛掉,害我去開檢討會議罰站一整天」
- 開發:「可是……在我電腦上是好的!」……(經典名句啊 XD)
這種情況不會只發生在 Google ,也不只發生在開發和維運兩個部門之間,在世界上各個角落都會發生,也就是所謂的「穀倉效應」。(還有人專門寫成一本書)

簡單說就是各部門之間變成孤島,發生衝突之後,部門之間互不信任,使用各種措施阻礙對方:
- 維運:根據以前發生過的錯誤,準備一連串的 Checklist。
- 開發:強調這不是改版,是微調,可以直接上。
部門間從合作變成互相角力,拖慢了整個系統開發流程。
同樣的事情發生在 Google ,而 Google 又怎麼解決這樣的問題呢?
縮短交付時間
Google 在2003年成立 SRE Team (Site Reliability Engineering) ,組成如下:
- 50%~60%純軟體工程師。
- 40%~50%接近軟體工程師,兼有 SRE 技能(系統和網路專家)。
SRE 軟體工程師必須要
- 維運產品
- 建一個系統來執行「維運」的人工操作
Google 規定, SRE 只能花50%的時間解 ticket、on call、人工操作。
超過 50% 的部分,指派給開發團隊負責。
所以開發團隊則是要:
- 開發產品
- 如果 SRE 太忙,要幫忙分擔工作
所以 SRE 除了做維運,也要寫「維運」的程式,而開發團隊除了寫「產品」的程式,也要做維運。==>>產生交叉培訓。
也帶來了其他好處:
- 系統變大變複雜,卻沒有僱用更多人。
- 軟體更新速度保持不變。
- 軟體不用停機就可以直接進行修改。
快速回應使用者需求
同時來看看其他的例子,Line Engineering的部落格寫得很好:
IBM和微軟
「2家公司發現當他們還在以每季度在更新軟件時, Google 卻是每天都能更版甚至使用 A/B Testing 的方法在快速反應使用者的回饋。結果是 MS Office 轉型後且上了雲端似乎帶來更好的結果,但 IBM 卻退出了企業協作軟件的市場。」
以及Nokia的例子:
「2010 年當其董事會主席 Risto Siilasmaa 視察公司時發現,Symbian 作業系統建製一次需要 48 小時,對於當時的他猶如當頭棒喝,而內部雖然一直有淘汰 Symbian 的建議,卻一直沒被管理層所採納。」
這告訴了我們,速度真的是非常重要的因素,即使別人很晚才進入巿場,只要他開發速度比你快得多,你總有一天會被他超車。
什麼時候要導入 DevOps ?
那什麼時候要導入 DevOps 呢?只要有以下症狀,都可以考慮看看:
- 開發部門無法在開發早期偵測軟體缺陷
- 無法確定問題出現在哪一個部門
- 人為錯誤經常發生
- 只要部署出去, Dev 就認為工作完成
- 問題發生,相互指責
DevOps 導入 5 大原則
那要如何導入 DevOps 呢?五大原則如下:
- 接受失效(Failure),視失效為開發週期中的一個元素
- 減少組織之間的穀倉效應
- 持續改善
- 善用工具和自動化
- 任何事都是可以被量測的
SRE 工程師實作 DevOps 5 大方法
DevOps 畢竟是大原則,而 Google 在這部分使用 SRE 作為具體的實做方式,分述如下:
設定錯誤預算
預算指的不是錢,而是時間(雖然時間可以折算成錢)。這裡要先提一下 SLI (Service Level Indicators)、 SLO (Service Level Objects)和 SLA (Service Level Agreements)的簡單定義:
- SLI :和系統效能有關的指標,例如 Latency或Throughput等等。
- SLO :表示我們希望 SLI 有多少,但這個不會公佈出來,是公司內部自訂的。
- SLA :是對客戶保證,每年或每月的停機時間不能超過多少時間,如果是公開的應用程式,是會宣告出來的,如果是開發給某客戶使用,就是和客戶談出來的,會寫在合約上。如果停機超過 SLA 所訂的時間可能是要賠錢的!
Google 在 SRE Book 有直接換算在不同的 SLA 和單位時間底下,最長的中斷時間各為多少:
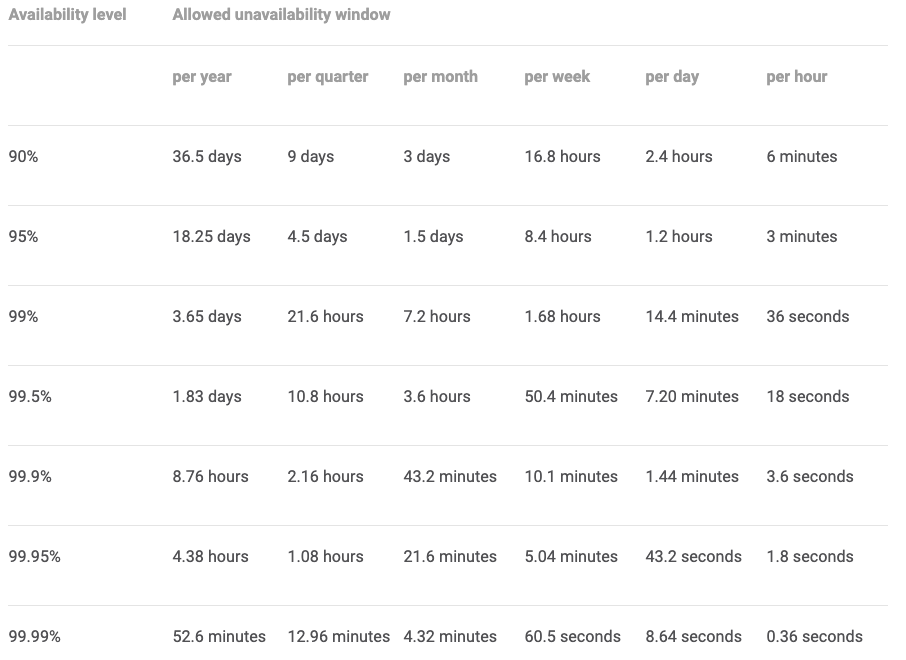
但這不是給你拿來跟客戶說:「你知道嗎?我們家的系統最多可以斷三天喔!」這樣你可能會被踢出去。
你可能會問,為什麼不做到 100%呢?

就像我們去考試一樣,從90分進步到99分比較容易,還是從99分進步到100分比較容易?
Google 的解釋是這樣的,為了達到 SLA 100%,中間有太多不可抗力因素,例如從你的應用程式傳訊息要先到電信商的基地台,中間可能已經是99.9%的 SLA ,再從基地台傳到你的手機可能又是99.9的 SLA ,這裡都還沒算到你開發的應用程式可用性, SLA 就已經是98.9%了,那你要怎麼做到100%?
先買下電信商,再買下那支手機的製造商,然後請超厲害的工程師把APP寫到100分?然後呢?你做到 SLA 100%了,客戶感受到你0.1%的進步嗎?客戶願意為了你0.1%的進步而多付100萬嗎?
我們回過頭來講錯誤預算,直白一點的意思是「在沒有超過約定好的中斷時間之下,我們有多少時間可以拿來做一些創新的嘗試」。所以錯誤預算可以:
- 培養不究責的文化 Blamelessness => 以利事後調查
- 允許犯錯 => 鼓勵創新
- 用來承擔 Launch 的風險 => 做到快速 Launch
這看起來有沒有像我們學生時代,老師對我們的教誨,不要怕犯錯,Try and Error?
現在呢?多做多錯,少做少錯,不做不錯。歡迎來到大人的世界。大人講的都是對的嗎?官越大,越正確,你不知道嗎?(怨念好深……)
是的,現在是團隊合作的社會,為了不造成別人麻煩,或怕被懲罰,或是怕犯錯變成別人攻擊的對象,我們總是避免犯錯。為了避免犯錯,我們就不再創新了。槍打出頭鳥啊~ DevOps 第一條原則就把我們的臉打得好腫。

導入 Infrastructure as Code
Infrastructure as Code(IaC),中文意思是「基礎架構即程式碼」,就是盡可能讓環境,用統一規管的格式或設定檔(例如 yaml 檔)來部署,而不是人為去設定網路和伺服器等:
- 讓 開發/測試/生產 環境長得幾乎一模一樣,提早發現錯誤
- 可以被版本控制工具所管理 (如 git),這代表任何的改變都有跡可尋
- 減少人工所產生的錯誤
- 達成自動化

這樣如果一套程式在開發環境run不起來,在測試或生產環境一樣run不起來,要發現錯誤容易的多,大家一起來看 yaml 檔就好了。而且誰做錯全部的人都知道,不用推責任給別人,也不用故意放大檢視他人,大家心裡知道就好,犯錯的人也會默默檢討,毋需指責。
使用 CI/CD
什麼意思?誰不會持續改善,每個人都會不是嗎?聽起來好像廢話。
這裡講的持續可以用「漸進」來解釋,以前系統要改進,可能是收集完使用者回饋的100項缺點,一口氣全部改完再給使用者,就跟瀑布模式的系統開發流程一樣,常常要交付給使用者時才發現跟原始的需求不一樣。
所以這裡強調的是,只要修正一個點,就交付給用戶測試看看,測試OK再改下一個,這裡用到的具體做法就是 CI/CD。
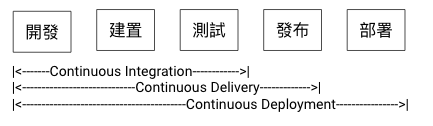
CI/CD 是什麼?
CI/CD 是軟體敏捷式開發中「持續改善」理念的具體作法。其中 CI 指的是持續整合,CD 可視團隊狀況定義為持續交付或持續部署。
- CI(Continuous Integration):持續整合
持續驗證開發結果 ,小部分小部分地儘早確認,期望產出符合需求,或依據產出進行快速修正。
- 建置 (build)
- 測試 (test)
- 程式碼分析 (source code analysis)
- CD(Continuous Delivery):持續交付
發行到測試環境,確保軟體持續保持在隨時可以釋出的狀況。
- CD(Continuous Deployment):持續部署
自動部署到生產環境。
減少手工(Toil,又稱工人智慧)
什麼是手工呢?手工的特徵如下:
- 手動執行 script、開關機、上新版程式
- 對每個新客戶進行的重複性工作
- 沒有永久的價值(長期的改善)
因為這些工作是不斷重複的,因為重複就會感到單調,因為單調做起來就覺得很沒勁,甚至厭煩,久了甚至會忽視,不專心地做這些事情,這樣出錯的機率反而就會提高。
我曾經在以前的某個公司,也做過某件明明對公司就非常重要,卻沒有人重視也沒有人關心的「手工」,剛好有一次工作太忙,又覺得自己做很多次自以為熟悉,就忽略了一兩個檢查步驟,然後好死不死就剛好系統有問題沒檢查到,造成最後一條龍的流程全部受到影響,並且要全部重來,最後在檢討會議上給別人盯,這就是究責的文化啊~
別讓昨天在你傷口狂忘的撒鹽,一碰就痛,一想就悲。(明明就我自己撒的)
所以自動化說有多重要就有多重要,並且搭配漸進式部署 (Progressive Rollout)
- 一次發布一點點變動,並且針對少量使用者發布,每次的變動都可以密切地監控效能是否有什麼影響。
- 快速準確地發現問題。
- 出現問題時安全地回滾更改。
- 只要錯誤減少,產品交付就會加快。
而自動化的工具很多,非常多,還有公司直接弄成元素周期表,之後我們也會再分享在 GCP 實做的相關工具。

讓流程透明化並加以監控
這一點是跟 CI/CD 最大的差異之處,它強調的重點如下:
- 監控是追蹤系統健康和可用性最好的方法
- 如果必須要有人閱讀電子郵件, 並判斷是否需要採取行動的系統,從根本上是有缺陷的。
- 只有一定要採取行動的時候,系統才發出通知。
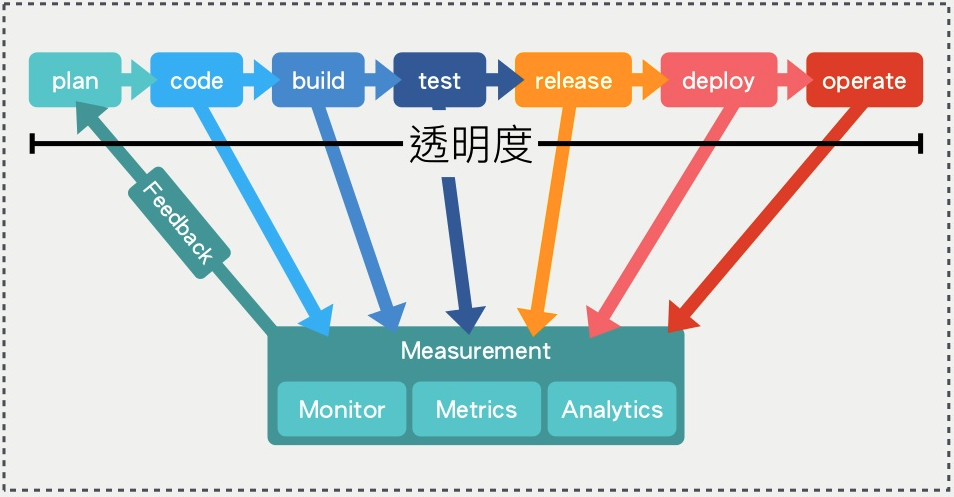
資料來源:提到 DevOps 到底在談些什麼玩意兒?
跟之前「減少穀倉效應」的概念類似,就是要讓所有事情都透明化,所以才需要「監控」這個關鍵步驟,這樣發生任何事,都能快速找到原因,而不是浪費時間在那邊跟別人吵架。
其實,以上提到的實施方法,就是 Google 提出的 SRE (Site Reliability Engineering) 概念:
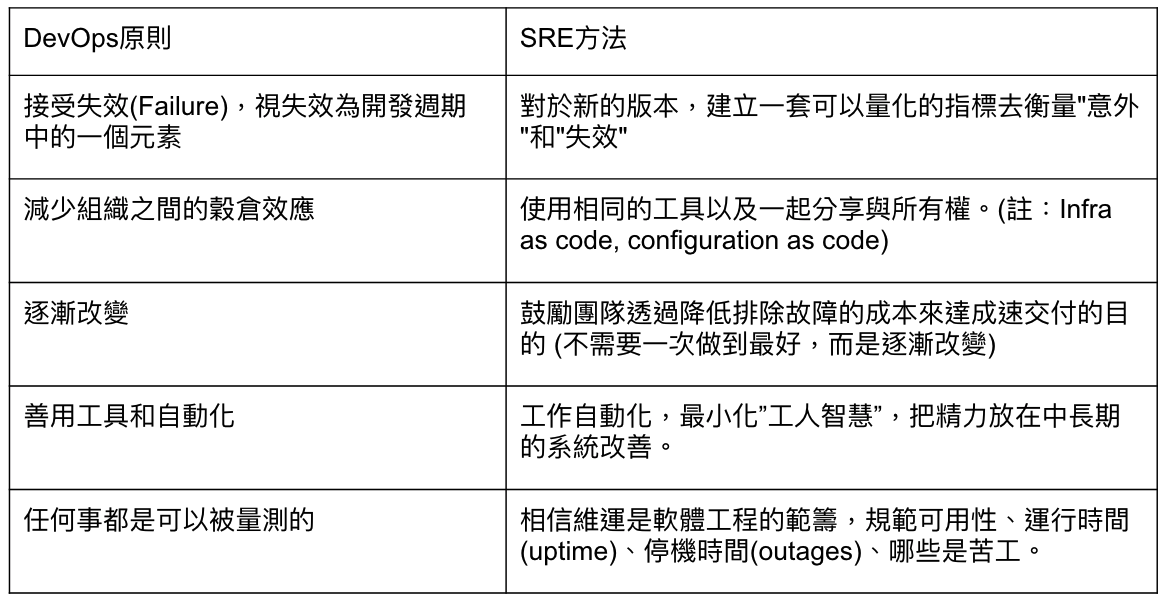
資料來源:[好文翻譯] 你在找的是SRE還是DevOps
各位有空真的可以去讀一下 Google 的 SRE Book,非常適合在睡前看持續成長的你。或是參考《維運管理與 SRE 的關係》這篇文章,快速了解維運管理和 SRE 之間的關係
最後 Google 還說,方法歸方法,「人與文化」還是推動 DevOps 最關鍵的因素,我們非常需要高階主管的支持, DevOps 才動得起來。 Google 為了推動 DevOps 文化,曾經在公司內辦了大大小小的說明會,就是為了打造一個具有「心理安全」(Psychological Safety) 的環境,更何況是我們,有更多需要「人與文化」改善的地方啊!
最後的最後,如果針對 DevOps 和 SRE 還有相關疑問,歡迎留言詢問或直接聯繫我們。需要 DevOps 導入協助的話也可以參考我們的解決方案說明喔!
▋延伸閱讀:
・代管式 Kubernetes 介紹 – GKE:比 K8s 更好用的 DevOps 工具
・DevOps 教學:利用 GitLab、GKE 五步驟達成 CI/CD
・DevOps 教學:以 Google Cloud 工具達成 CI/CD
・維運管理與 SRE 的關係


