文章段落
透過機器學習,我們可進行更深度的數據分析,但對缺乏相關專家的企業而言,機器學習始終是個難以跨足的領域。而為讓機器學習更為普及,Google 推出眾多好上手的工具,讓企業能更輕鬆地深度洞察數據中蘊含的商機。
機器學習普及化的必然性
根據麥肯錫的報告,到2030年,完全採用人工智慧技術的公司現金流可能會提高一倍,而沒有採用的公司可能會有20%的損失。機器學習和人工智慧在傳統上被視為博士和專家的領域,因此,許多企業主將實踐機器學習這個目標設為人力資源部的挑戰(包含創建新部門、僱用新員工、為現有員工制定留才計劃)也就不足為奇了。但這不是必要的,Google Cloud 不僅專注於提高專家效率,還將機器學習引入任何使用資料的工作者日常。
針對上文提及的專家,也就是傳統的機器學習使用者,Google Cloud 建立了一整套工具。Vertex AI(原:AI Platform)使他們能輕鬆快速地迭代並有效地將想法具體實現。在機器學習團隊中,AI Hub 使團隊成員間的協作變得更加容易,避免重複工作流程並加速工作的完成。最後,TensorFlow Enterprise 提供可擴展的雲端版 TensorFlow,讓專家們更靈活、快速地增加產出,從而擴大公司內部對機器學習的使用。
但要真正將機器學習整合進整個組織中,我們需要創建能讓更多角色來獲得可行洞察的工具。讓我們看看 Google Cloud 正透過什麼使機器學習普及到三種關鍵角色:資料分析師、開發人員和資料工程師。
資料分析師入門機器學習的利器― BigQuery ML
資料分析師是許多財經雜誌前500強公司的支柱,他們是資料倉儲專家,除了非常熟悉 SQL ,對業務需求更是瞭如指掌。我們知道,要賦予這個角色機器學習能力,需從他們本身的強項著手。
這正是 BigQuery ML 所做的事。它將機器學習帶入資料倉儲領域,並使用相較 Python、R 語言和 Scala,資料分析師更為熟悉的 SQL 語句進行部署。當結合 BigQuery 的能力,我們可將資料量擴增到比傳統企業資料倉儲更大的規模,BigQueryML 使資料分析師能在大量資料中驅動機器學習,發掘前所未有的洞察。BigQuery 中有多種模型可幫助客戶採用各種實際案例,如推薦系統、分類、異常檢測和預測。此外,如需自訂模型,機器學習專家可建構模型並匯入 BigQuery,分析師則可用來處理大量資料。
我們已經看到不同產業的客戶使用案例成功部署 BigQuery ML。Telus 使用機器學習部署異常檢測以保護網路環境;UPS 用來實現精確的包裹量預測;Geotab 透過融合機器學習和地理空間分析推動智慧城市,我們甚至已看見 BigQuery ML 被部署來預測電影觀眾。此外,我們更看到零售商預測購買行為;金融服務機構判定保險風險;遊戲公司預測長期客戶價值。過去,資料分析師不可能進行這種分析,但今天它不僅高效,還擁有非常高速的實施捷徑。
隨著 BigQuery ML 的功能不斷增長,精通資料的團隊成員無需再學習將大量資料匯入與匯出 BigQuery 的專業知識,以及學習如何同步與擴展資料管道以處理部署作業。透過直接在 BigQuery 中進行資料清理、模型訓練和部署,您可以將更多時間花在理解資料並從中創造價值上,而非四處遊走。
Daniel Lewis,Geotab 高級資料科學家、研發專家
開發人員入門機器學習的利器― API、AutoML
針對開發人員,我們開發了兩種不同類型的服務,它們使機器學習大眾化,並在創建應用程式的過程中充當「積木」。第一個是一組容易藉由 API(應用程式介面)進行存取的預訓練模型。這些 API 解決了視覺、語言和對話等方面的多種使用案例。對於需要更多特殊性的模型,如識別特定品牌的所有卡車,而不是卡車的一般性識別,Google 提供 AutoML 自訂模型,使開發人員能建構特定領域的客戶模型。這些工具為 Keller Williams、今日美國、普華永道、AES Corporation 等公司提供了支援。
借助 AutoML Vision,我們近一半的檢測圖像不再需要人工審核。Google 是一個很好的合作夥伴,因為他們的技術始終位處世界領先地位。
Nicholas Osborn,AES 數位中心總監
在大規模構建機器學習模型時,AutoML Tables 使開發人員(以及資料科學家和分析師)能以驚人的速度在結構化資料上自動建立和部屬機器學習模型。無代碼(Codeless)介面不僅使任何人都能輕鬆構建模型並將其整合到更廣泛的應用程式中,還可節省時間與資金,提高部署的模型品質。使用 AutoML Tables,我們看到客戶交付的行銷計劃在正確的時間和地點與正確的用戶溝通,每花費1美元就能增加150%的訂閱用戶,並取得高達140%的行業平均用戶參與度。
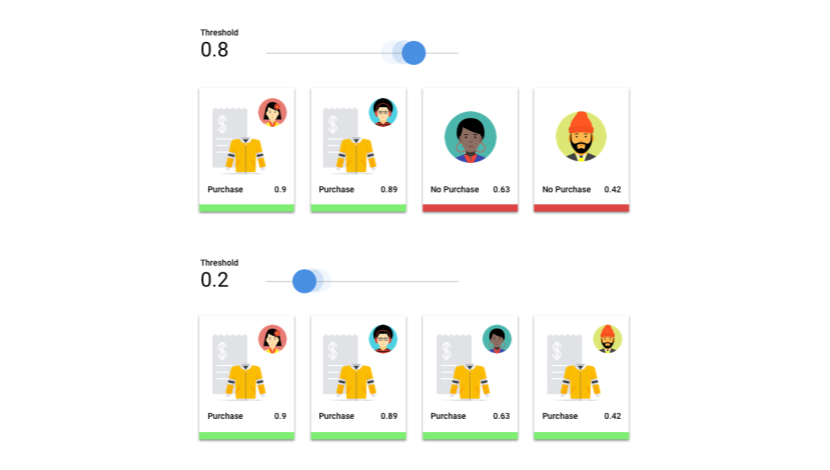
©2022 Google
此外,這些機器學習 API 不僅支援應用程式開發人員,使用 Cloud Data Fusion 的 ETL (Extract-Transform-Load)開發人員,也能輕鬆將這些 API 介接到資料整合管道中,從而為後續的應用程式與用戶賦予能量並提供分析的準備。機器學習現在就像滑鼠的移動、點擊和拖放一樣簡單。
資料工程師入門機器學習的利器― Dataproc、Dataflow
我們討論機器學習普及化的最後一個角色是資料工程師。值得一提的是,我們討論過的所有角色都受益於 Google Cloud 的自動擴展特性,這消除了運轉機器學習模型需頻繁調整設定的時間,不然這項工作可能不成比例地落在資料工程師身上(或在他們建立模型時,這項工作簡直把資料學家當成資料工程師在用)。我們努力將機器學習功能嵌入到我們在 Google 看到的兩個資料工程發展路線:Dataproc 導向的開放原始碼路線,以及雲端原生的 Dataflow 路線。
對於開源擁護者和那些熟悉 Hadoop 與 Spark 的人,Google 讓它很容易在使用者構建的 SparkML 作業上運行。Google 有一個易於運轉的 Qwiklab,它可帶我們透過 Dataproc 上的 Spark 了解機器學習的概念,用戶可免費試用。此外,Google 還讓客戶能在自訂的機器上建構自訂的 OSS Cluster,並快速將 GPU 驅動的機器學習帶給我們的客戶。結合先前宣布的功能,Dataproc 用戶現在可透過操作好用的 Notebook 環境,和排程刪除 Cluster 等功能快速部署機器學習。

©2022 Google
對於使用 Dataflow 的資料工程師,Google Cloud 讓使用 Tensorflow Extended(TFX),在生產環境中建構和管理機器學習工作流程變得輕鬆簡單。透過 Apache Beam(Dataflow 的 SDK),這樣的整合產生了一個建構機器學習管道的工具包、一組可用作管道或機器學習訓練腳本的標準零組件,以及用於許多標準零組件的基本功能函式庫。Google 的解決方案團隊正在努力使發布異常檢測等常見模式變得更加簡單,電信公司能將其用於網路安全;而銀行則以其檢測金融詐欺。
結論
將機器學習功能導入上述這些新角色,使大數據在各方面普及化,如:產生幫助企業驅動預測、新客戶群和推薦等功能的洞察。機器學習提供的進一步深入洞察,對業務成功這塊將越來越重要,這意味著成功的企業將成為能廣泛部署機器學習和人工智慧的企業。在 Google,最好的想法往往會脫穎而出而非被推翻。當整個組織都能存取到資料和分析資料的工具時,我們就可以為接下來的一切做好準備了。如果想立即嘗試機器學習,BigQuery Sandbox 是開始試用 BigQuery ML 的絕佳(免費)去處。
以上就是 Google Cloud 中可讓不同領域人員更好上手機器學習的工具介紹,大家如針對文中內容有任何問題,或想看特定內容都可在下方留言。最後,想更了解 Google Cloud,或有技術服務相關需求也都歡迎填寫表單聯繫我們。
▋延伸閱讀:
・BigQuery 是什麼?大數據時代一定要認識的最強資料分析工具
・BigQuery 教學―操作界面與分析、視覺化步驟完整圖解
・BigQuery 與 Data Studio 的經緯度資料分析
・立即實踐大數據分析應用!步驟、工具、目標建議一次了解
資料來源:Google Cloud Blog